SHA1 hashes are long, ugly, and unwieldy. That’s why Linux kernel developers refer to a commit in the git repository using a 12-character-long “abbreviated” commit prefix. One common usage of such commit prefixes is to indicate that a patch fixes erroneous behavior introduced by a previous commit via a “Fixes” tag, which includes the commit prefix and the shortlog in parenthesis:
Fixes: 48bcda684823 ("tracing: Remove definition of trace_*_rcuidle()")
Recent concern over collisions between such prefixes has been a topic of debate on the kernel mailing list1. At length, Jonathan Corbet applied a patch2 to the kernel documentation which made it clear that abbreviated identifiers should be at least 12 characters long, optionally longer.
You might imagine my surprise, then, when Greg KH let me know that my 16-character prefix was too long3. What gives? One would hope that a seasoned kernel maintainer would be mindful of the impending doom of too-short prefixes. Unless, of course, developers worried about collisions are simply paranoid…
The End of Days
So what exactly did Geert Uytterhoeven mean when he said “collisions of 12-character commit IDs are imminent”?
The issue can be modeled by the Birthday Paradox, which describes the
counterintuitive (read: paradoxical) fact that if you select 23 people
randomly, the probability that at least two will share the same birthday
surpasses 50%. Parameterizing the number of people as n (number of commits)
and the number of days in a year as d (total number of unique objects
addressable by a 12 character prefix), we get the following equation for the
probability that there is at least one commit prefix collision (assuming
n < d):

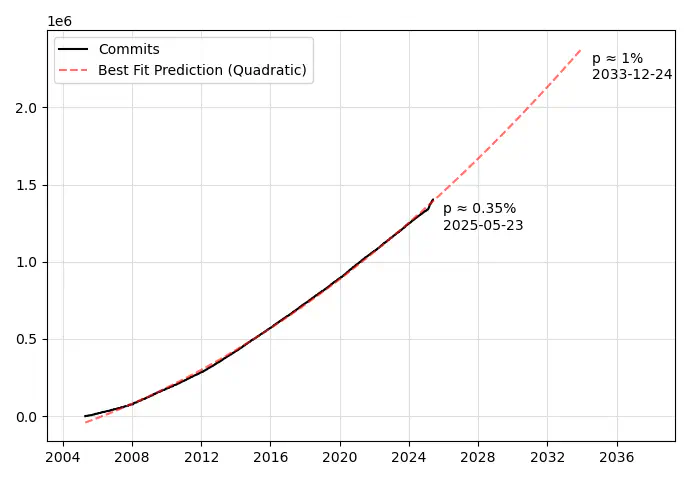
At the time of this writing, my local clone of linux-next contains 1,402,403
commit objects4 (You will see a slightly larger or smaller number of commits
at any given time depending on which branch you’ve cloned). This yields a
probability of 0.00348753 ± 3.56E−9 that any two commits share
the same 12-character commit prefix5. That’s little more than a third of a
percent.
The probability of just a single collision in the entire Linux kernel git history isn’t likely to crest 1% until the kernel eclipses 2,378,620 commits in approximately late 2033. However, it may be worth revisiting the preferred git commit prefix length when that time comes, as the probability of collisions increases sharply from that point on.
Collision Schmollision–Who Cares?
Of course, all of this is assuming that the kernel development process can’t tolerate even a single collision between prefixes. Linus argues that a single prefix referring to more than one commit is a non-issue. Kernel hackers should actually be worried about the much more impactful, more present issue of prefixes that don’t refer to any real commits at all6:
Using git, there are two main operations to integrate changes from one branch
into another: merge and rebase. Of the two, rebase is the only one which
modifies the pre-existing commit history. Normally that’s not such a bad thing,
but modifying the history causes commit IDs to be recalculated. After a
developer rebases, all Fixes tags which refer to a commit in the rebased
history are now invalid and forever broken.
By design, the commit shortlog of a broken Fixes tag can likely be used to uniquely identify which commit it belongs to, even if the commit ID is incorrect.
A quick shell script7 reveals that the vast majority of Fixes tags in
linux-next have an unambiguous commit prefix. The vast majority of ambiguous
tags (either rebased or otherwise lost to bitrot) can be disambiguated via a
unique commit shortlog. A total of 198 Fixes tags are floating around with
broken commit prefixes and non-unique (or non-existent) commit shortlogs:
Unambiguous Tags: 116723
Disambiguated Tags: 1031
Ambiguous Tags: 198
Clearly, Linus has a point: While there are yet no collisions of 12-character commit prefixes in the kernel, the problem of 198 (give or take, depending on the branch) broken Fixes tags is running rampant, relatively. Making already-unsightly 12-character prefixes longer solves no actual problem.
There may be something to be done about the problem of rebasing breaking tags: Change git to create a new object upon rebasing which acts as a symlink from the old commit ID to the new commit ID. Of course, this would require significant changes to git plumbing and may even require changes to tooling that integrates with git: we’re splitting hairs with this approach.
If It Ain’t Broke, Fix What Is
Rather than change git fundamentally or increase the minimum prefix size, there are more low-hanging fruit that can reduce the chance of a prefix collision: Commits, trees, and blobs are all stored in the same git database, but any development tool should be able to use context to infer which kind of object it should search for. This reduces the likelihood of the collision of a commit prefix drastically.
Geert pointed out that cgit could use exactly this kind of improvement. When using cgit to view a commit, it should be able to tell the difference between a commit and a blob that share the same prefix, then correctly display the commit instead of the blob, but it doesn’t do this!
I whipped up a patch to make cgit correctly resolve the prefix using context clues8 and sent it off to the cgit mailing list. This change wasn’t difficult at all. Most tooling probably does something similar by now, but for the tooling that doesn’t do this, it’s a small change that can increase resiliency against collision greatly.
Conclusion
For the moment, there’s not much point in using more than 12 characters to abbreviate commits. Instead, kernel developers should turn their attention toward making existing tooling more robust. Along the way, we may find a solution to commit IDs lost by rebasing, but it will require more careful thought.
Personally, I’ll be changing my git config to generate 12 character commit prefixes instead of a paranoid 16. Dear reader, you have my apologies for wasting 4 bytes of your inbox per Fixes tag up until now.
https://lore.kernel.org/lkml/cover.1733421037.git.geert+renesas@glider.be/ ↩︎
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=6356f18f09dc0781650c4f128ea48745fa48c415 ↩︎
https://lore.kernel.org/lkml/2025052234-brewing-recall-a7ed@gregkh/ ↩︎
git cat-file --batch-check --batch-all-objects --unordered | grep commit | wc -l↩︎calculated using this program I rolled ↩︎
https://lore.kernel.org/lkml/CAHk-=wiwAz3UgPOWK3RdGXDnTRHcwVbxpuxCQt_0SoAJC-oGXQ@mail.gmail.com/ ↩︎